

引子:因本人工作与AI相关且爱好看球,故写作此文,初衷是以写作的方式督促自己持续学习。才疏学浅,尚多不甚明了处,欢迎探讨斧正。
又到了世界杯季,作为真球迷的我很是兴奋,然而比我更兴奋的是千千万万伪球迷。不知道为什么这次赌球之风尤为盛行,印象中14年世界杯和16年欧洲杯的热度远远不及本届赛事。
既然大家都认同科学技术是第一生产力,何不用科学的方法研究一下足球?如果以胜负预测为研究方向,作为当前热度最高的机器学习技术是当仁不让的首选武器,预测过程可以看成一个分类过程,整个训练过程则是一个以历程战绩、博彩赔率、球员能力等数据作为特征的有监督学习。
当然,这个想法早就有了,而且大部分已经在代码层面实现了。作为一个研究课题,我们首先来看一看国内外研究现状。
首先我想说的是预测比赛不会很靠谱,因为特征选择太难,人为因素也太多,所以做球赛预测模型的收益不大,所以也就是搞AI又喜欢看球的才会折腾折腾。可能是国人比较重视投入产出的缘故,玩这个的很少,国外倒是有很多爱好者在公开了他们的算法。
周六外面又阴雨绵绵,正好趁这片刻闲时,挑选互联网上传播最广的两套算法来了解一下。
这套方法来自肯尼亚投资银行的分析师Muriuki,他已将代码托管在github上[1]。
Muriuki的模型比较简单,数据来源与Kaggle数据集,特征只选取考虑了主客场类别的对阵数据,类别标记是胜平负,以逻辑回归作为分类算法。其中值得一提的是因为数据集中存在主客场区别,而世界杯除东道主外均为客战,为了保持数据一致性,作者引入FIFA排名,每场比赛中Rank靠前的设为主队(隐藏逻辑是排名靠前的球队拥有更多球迷),这是个有意思的想法,以此为起点可以引申出更多的主客场数据处理方法。
作者以70%的比例提取训练集,模型在测试集上的预测准确率为55%。小组出线形势的预测结果为: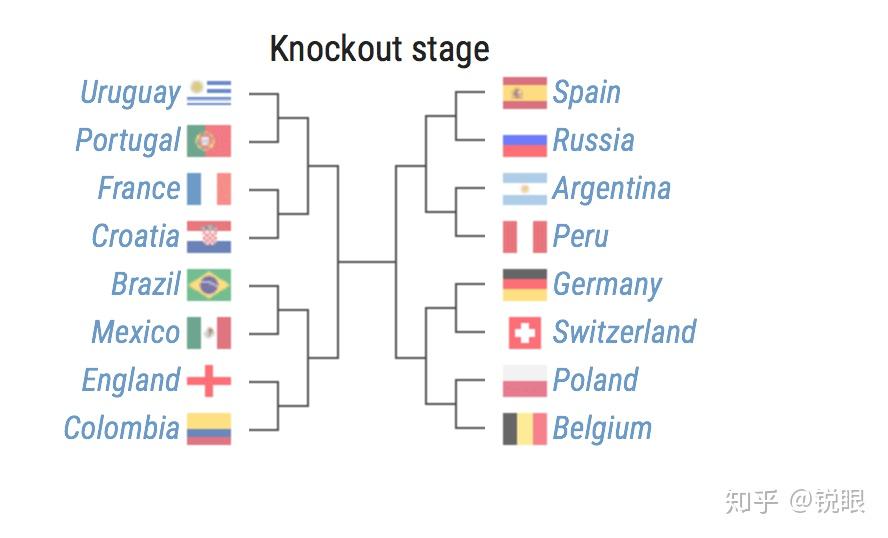
现在看来,秘鲁、德国、波兰已经凉了。模型预测决赛将在巴西和德国中产生,最终巴西将捧杯雪耻。针对德国队现在的状态对此结果我也表示怀疑。
逻辑回归是一种比较常用的分类算法,其优点是应用简单,先对特征向量做线性变换再用sigmoid函数激活,最后求最大似然;预测结果就是0/1之间的概率,直接明了。缺点是相比其他算法偏差偏高;处理大量特征时效果不好。对于线性不可分问题、多分类问题、共线性问题可分别用特征非线性化、softmax和L2正则化加以应对。现在已存在LR的分布式实现,计算效率进一步提升。以逻辑回归作为分类算法没有问题,毕竟特征太少,采用其他算法也有点杀鸡用牛刀的感觉。
此模型相当粗糙。首先,作者在附文中已明确表示,他不是资深球迷,因此在特征工程上比较偷懒,只有历史对阵成绩的特征可以表达的信息非常有限;其次,数据太过久远,粗略看了一下至少可以追溯到20世纪40年代,时效性是个问题;还有一个问题是将FIFA Rank作为判断主客场类别的依据只在预测过程起了作用,在数据集中有很多国际赛事并未以此方法做预处理。采用什么机器学习算法其实不甚重要,在这个问题上特征工程的作用更加明显。
此篇论文发表在arxiv上[2],作者是多特蒙德技术大学以Groll为首的AI科学家。
本文使用02到14年4届世界杯比赛数据,比较了三种不同的建模方法——Poisson Regressio-n、Random Forest和Ranking Method 在预测比分中的效果。前两种基于相关变量如比分、经济等对抗信息建模,第三种方法顾名思义,基于球队能力评价指标如球员实力、教练水平来建模。模拟结果显示后两种方法拥有更高的准确率,经验证将二者结合是更好的办法。最终,本文使用此结合算法计算了各队在各杯赛阶段的获胜概率。
作者在Introduction中系统介绍了近些年学者们的研究成果,最初的一个有效建模策略是基于博彩赔率的建模。之后学者们发现可以建立假设进球数服从泊松分布的统计模型,最简单的方式是附加条件独立假设,目前许多研究人员已经摆脱了这个强烈假设,这看起来是更合理的,因为进球数确实与对手有较强的相关性。与此完全不同的建模策略是采用随机森林的集成学习,在Groll在早前发布的初步研究结果表明随机森林提供了非常令人满意的结果[3]。
在数据层面,作者综合考虑了很多方面,最后挑选了如下特征。
1.经济因素:人均GDP、人口。
2.竞技因素:赔率(ODDSET)、FIFA排名。
3.主场优势:是否东道主、所在大陆、所在大洲。
4.队员结构:最大与次大俱乐部队友数,平均年龄、欧冠球员数、异国俱乐部球员数。
5.教练因素:年龄、执教期、是否与球队同国籍。
在方法层面,作者详细介绍了上文提到的几种建模策略。
1.随机森林:随机森林和GBDT都是常用的集成学习算法,对此早有耳闻,但遗憾一直惰于深入研究,其基本逻辑是通过建立大量独立的CART决策树后以投票或平均等方式集成各树结果,“随机”的意思是在每棵树中随机采样数据和在每个树枝随机提取特征,从而达到减少过拟合风险的目的。RF与GBDT的主要区别在于一个是并行模式,一个是串行模式。因为文章目的主要是预测比分,随意属于回归问题,故采用各决策树均值作为最终结果。
上图为训练后得到的特征重要程度,可以看出FIFA排名和赔率是影响最大的因素。
2.回归法:作者综述了各种回归方法,其中效果最理想的是结合L1正则化的泊松回归。进球数服从泊松分布是一个很传统的假设,比较随机森林之后发现此方法稍有逊色。
3.排序法:结合以往比赛进球数,结合泊松回归创建一个最大似然估计模型来对球队能力值参数进行估计。为了区分不同赛事和不同比赛年份的影响程度,作者分别引入了两种权重。在时间上借鉴了在放射性元素半衰期的概念,距离现在时间越久远的比赛重要程度越低,考虑到不同比赛的规模和重视程度不同,引入了FIFA排名计算方法,按世界杯、洲际杯、预选赛、友谊赛分别分配权重。
4.结合模型:最终作者比较了各个方法后,将用排序方法计算的球队能力值作为一个新的特征加入随机森林作为最终模型。
最终模型预测的各队夺冠概率如下: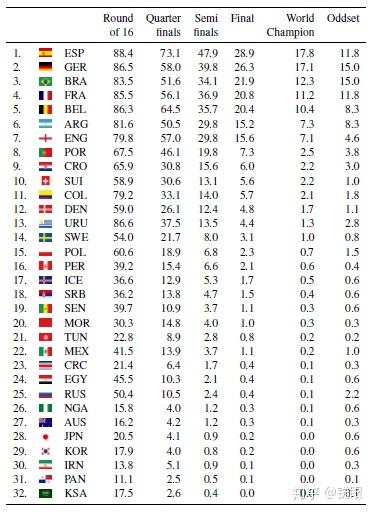
模型预测的各阶段各队胜率如下: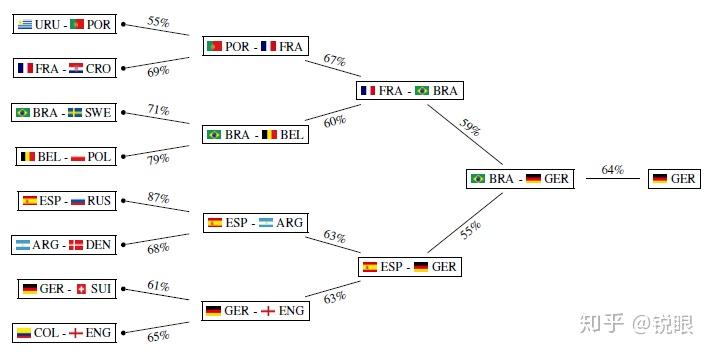
此文所描述的模型无论在特征工程还是学习算法方面看起来都很合理,尤其是在特征选择上考虑的很全面。看完论文觉得还有几点没搞清楚,比如进球数服从泊松分布的背后逻辑?球队所在大陆和所在大洲是否有必要区分为两个特征?博彩赔率数据结构如何,综合欧盘、亚盘?由于我对随机森林算法不够了解,所以后续有时间准备实现一下文中方法,顺便加深一下对随机森林的理解。
注:文中方法与结论具有随机性,本文不构成任何博彩建议,好好看球,远离赌博~
[1] itsmuriuki/FIFA-2018-World-cup-predictions.
[2] [1806.03208] Prediction of the FIFA World Cup 2018
[3] Schauberger, G. and A. Groll (2018):“Predicting matchesin interna- tional football tournaments with random forests,” Statistical Modelling, in press.
公众号:锐眼出版社


文章声明:以上内容(如有图片或视频在内)除非注明,否则均为欧洲杯直播_足球直播_无插件免费高清体育直播表原创文章,转载或复制请以超链接形式并注明出处。
本文作者:admin本文链接:https://guoshizhichan.com/post/627.html



